
Штучний інтелект та забуті мови
У світі десятки мертвих мов, про лексику, граматику та синтаксис яких немає інформації. У наш час зберігається дуже мало текстів зроблених мертвими мовами, тому для алгоритмів машинного перекладу, таких як Google Translate, наприклад, цієї інформації недостатньо.
Деякі мови навіть не мають звичних для нас розділових знаків та пропусків — це і було проблемою для розуміння текстів алгоритмами.
У Массачусетському технологічному інституті розробили нейромережу, яка допоможе лінгвістам розшифрувати давно забуті мови.
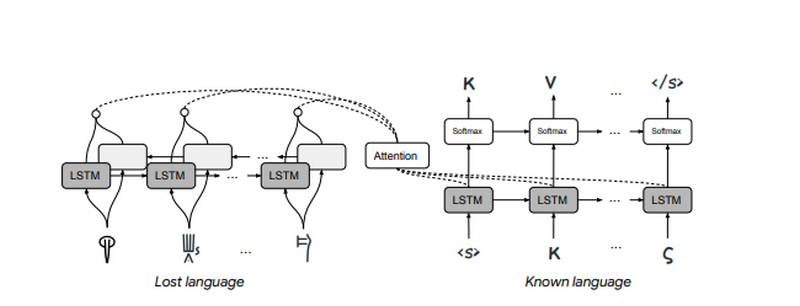
Принцип роботи штучного інтелекту
Окрім того, штучний інтелект навіть вміє розрізняти відносити між мовами — яка з них до якої мовної родини точно належить.
Нещодавно нейромережа навіть визначила, що насправді іберійська мова не має жодного зв’язку з баскською — хоча довгий час думали, що вони між собою пов’язані.
Робота системи будується на базових принципах лінгвістики. Наприклад, науковці, які вивчали стародавні мови, визначили, що літера «p» в словах з часом може змінитися на «b». Алгоритм зібрав шаблони зміни мови та розпізнає стародавні тексти.
Надалі вчені планують додати більше можливостей для нейромережі. Вони хочуть навчити її розрізняти семантичне значення слів. Тобто система аналізуватиме усі згадки людей, місць та шукати відповідники у вже існуючих історичних ресурсах, аби знайти можливе значення слова.
 ? Автопілот Tesla втік від поліції у Канаді, поки водій та пасажири спали
? Автопілот Tesla втік від поліції у Канаді, поки водій та пасажири спали