
Štučnyj intelekt ta zabuti movy
U sviti desjatky mertvyh mov, pro leksyku, gramatyku ta syntaksys jakyh nemaje informaciї. U naš čas zberigajeťsja duže malo tekstiv zroblenyh mertvymy movamy, tomu dlja algorytmiv mašynnogo perekladu, takyh jak Google Translate, napryklad, cijeї informaciї nedostatńo.
Dejaki movy naviť ne majuť zvyčnyh dlja nas rozdilovyh znakiv ta propuskiv — ce i bulo problemoju dlja rozuminnja tekstiv algorytmamy.
U Massačusetśkomu tehnologičnomu instytuti rozrobyly nejromerežu, jaka dopomože lingvistam rozšyfruvaty davno zabuti movy.
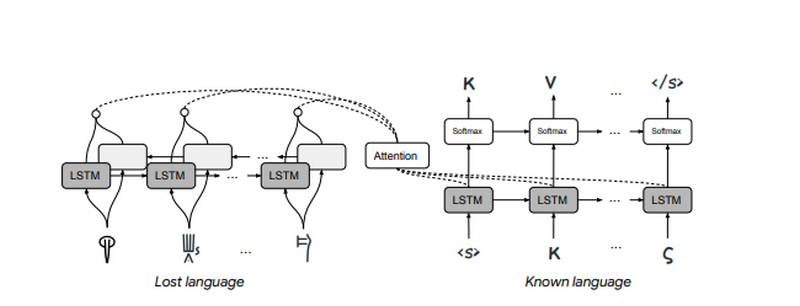
Pryncyp roboty štučnogo intelektu
Okrim togo, štučnyj intelekt naviť vmije rozriznjaty vidnosyty miž movamy — jaka z nyh do jakoї movnoї rodyny točno naležyť.
Neščodavno nejromereža naviť vyznačyla, ščo naspravdi iberijśka mova ne maje žodnogo zv’jazku z baskśkoju — hoča dovgyj čas dumaly, ščo vony miž soboju pov’jazani.
Robota systemy budujeťsja na bazovyh pryncypah lingvistyky. Napryklad, naukovci, jaki vyvčaly starodavni movy, vyznačyly, ščo litera «p» v slovah z časom može zminytysja na «b». Algorytm zibrav šablony zminy movy ta rozpiznaje starodavni teksty.
Nadali včeni planujuť dodaty biľše možlyvostej dlja nejromereži. Vony hočuť navčyty її rozriznjaty semantyčne značennja sliv. Tobto systema analizuvatyme usi zgadky ljudej, misć ta šukaty vidpovidnyky u vže isnujučyh istoryčnyh resursah, aby znajty možlyve značennja slova.
 ? Avtopilot Tesla vtik vid policiї u Kanadi, poky vodij ta pasažyry spaly
? Avtopilot Tesla vtik vid policiї u Kanadi, poky vodij ta pasažyry spaly